Have you ever wondered how platforms like Netflix recommend movies and TV shows based on what you’ve watched? Or how social media feeds seem to know exactly what interests you? The answer lies in data pipelines.
Data pipelines are robust systems that gather, process, and analyze data to deliver insights that power personalized experiences. In this blog, we will explore data pipelines, key concepts involved in their creation, and the tools that make building data pipelines easier.
Let’s dive into the essentials and understand how these tools help streamline the process of turning raw data into actionable insights.
What is a Data Pipeline?
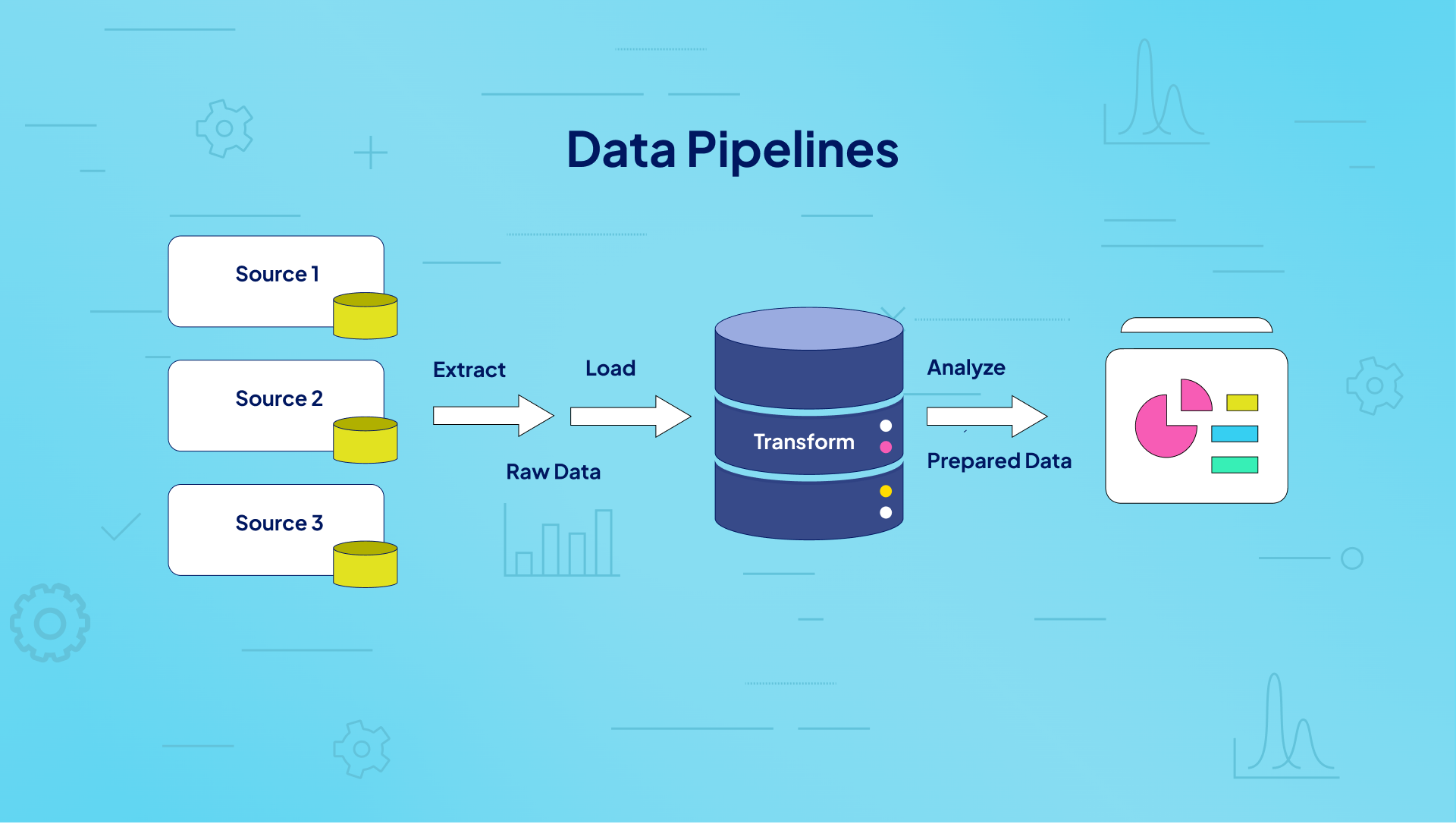
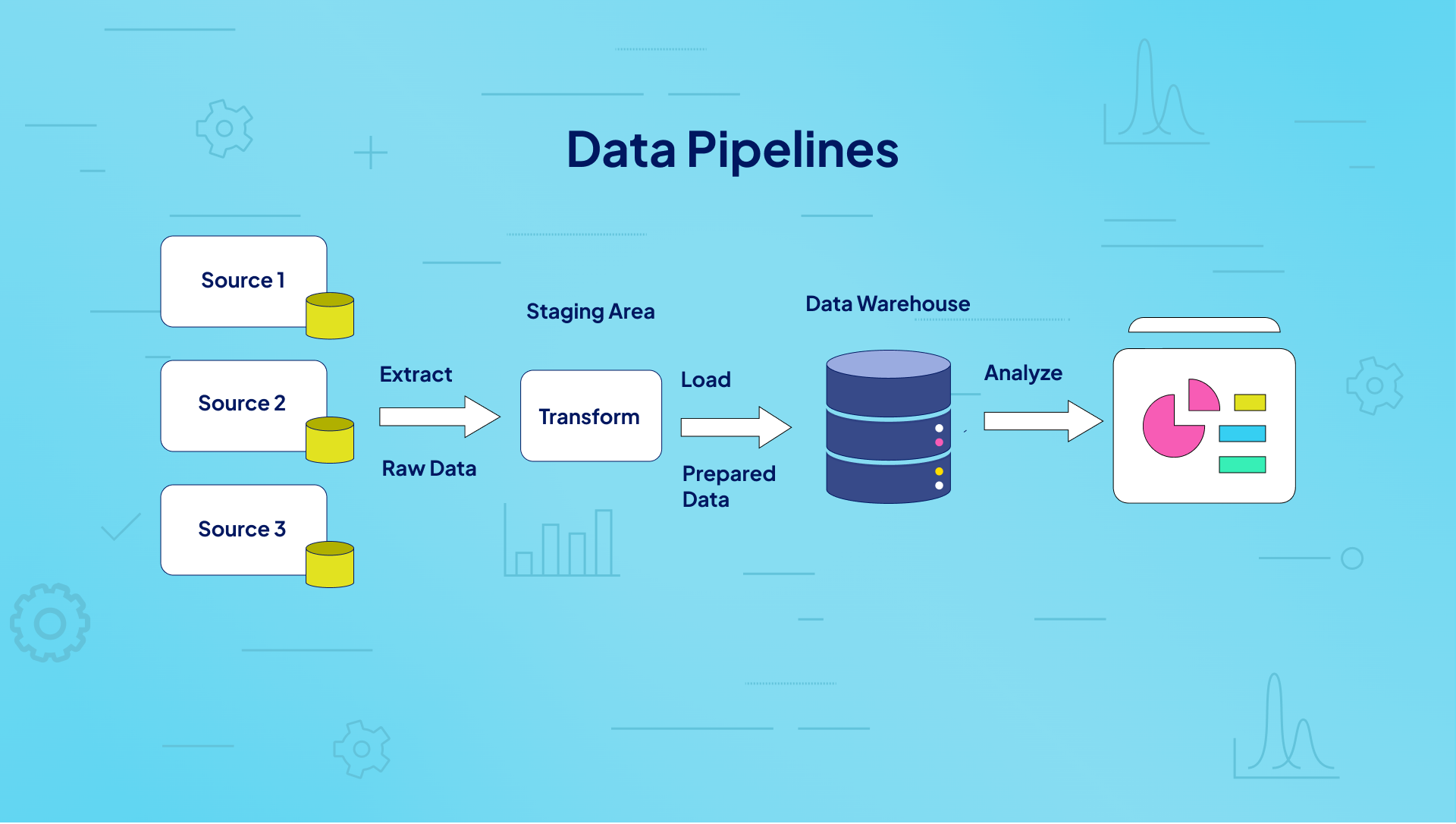
A data pipeline is an automated system designed to efficiently move, transform, and manage data between various points in a computing environment. It’s essential for modern data-driven organizations, facilitating the smooth flow of information through each stage of data processing.
In a data pipeline, data typically flows through a series of processing stages. Each stage processes and passes data to the next step, creating a streamlined sequence that continues until the pipeline completes its operations.
What are Six Key Data Pipeline Components?
How to Create Data Pipelines in Eight Steps
Now that you understand what is a data pipeline and its building blocks, let’s move on to
a step-by-step guide on how to create data pipelines:
Step 1: Define Your Goals
Start by understanding the objectives of your data pipeline. Clarifying the goals ensures the pipeline aligns with business needs and desired outcomes.
Step 2: Identify Data Sources
Identify where the data will come from, such as APIs, databases, or third-party systems. This step helps determine the types of data to work with and how to connect them.
Step 3: Determine the Data Ingestion Strategy
Decide how data will enter the pipeline—whether via batch or real-time processing. This ensures the pipeline handles data flow as needed.
Step 4: Design the Data Processing Plan
Plan how data will be cleaned, transformed, and enriched for analysis. This step ensures data quality and prepares it for downstream use.
Step 5: Decide Where to Store the Information
Choose a storage solution like a database, data lake, or warehouse. The storage decision impacts data accessibility and scalability.
Step 6: Establish the Workflow
Create a sequence of processes that define how data moves through the pipeline. A well-organized workflow is essential for smooth operations.
Step 7: Set a Monitoring Framework
Implement tools to monitor performance, errors, and resource use. This helps maintain the pipeline’s efficiency, accuracy, and reliability.
Step 8: Implement Data Consumption Layer
Make processed data available for users or applications, such as through APIs or dashboards. This step ensures that the data can be accessed and used effectively.
Common Tools and Technologies for Building Data Pipelines
Here are five data pipeline tools:
Onetab.ai
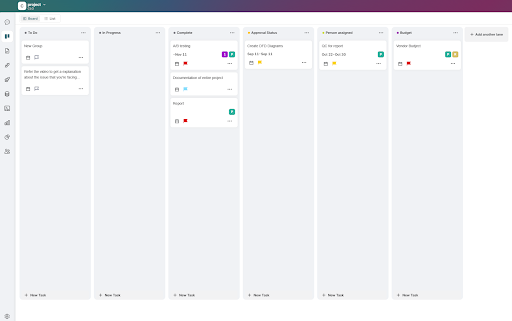
Onetab.ai is a powerful project management platform designed for teams to unlock a new plane of productivity. It features an intuitive and user-friendly layout that can meet several objectives, from task management to team collaboration to data management to reporting—and more! Plus, you can switch between different views to visualize your data pipeline the way you want. Onetab.ai also offers various ways to customize how you use the platform, allowing you to configure it based on project, client, or industry-specific requirements. Such versatility makes it a prime pick as a data pipeline tool.
How to create Data Pipeline with Onetab.ai
To create a data pipeline in Onetab.ai, use its integrated tools in conjunction. One API helps with API management as you collect data from various sources. One Database, which maintains database connectivity, helps with data storage, management, organization, and retrieval. Finally, One Analytics and One Ask generates insights and helps with data visualization.
Get instant insights from your data with One Analytics
Onetab.ai Pro
- Centralizes all data-related activities and operations into a single platform for more focused work
- Allows data pipeline visualization as Kanban Boards or Lists
- Generates detailed reports to support data extraction and analytics
Onetab.ai Cons
- The free plan is available only for a month
- The platform is still in its growth stage
Onetab.ai Pricing
- Kickoff Plan: $0
- Team Collaboration: $3.99
- Growth Plan: $9.99
Apache Airflow
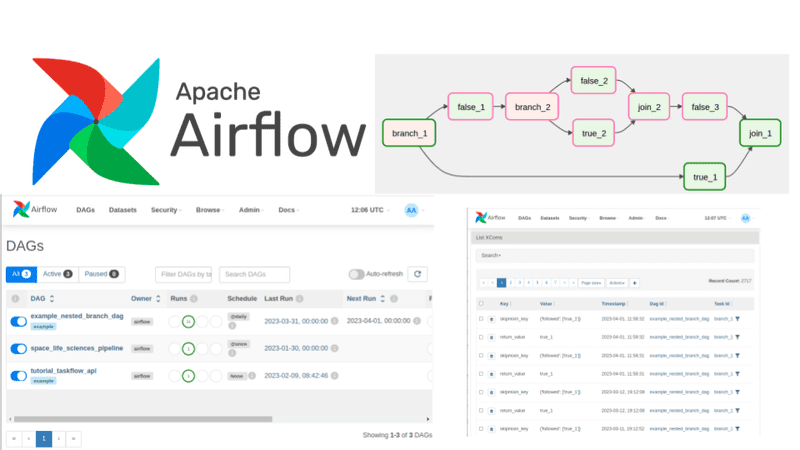
Apache Airflow is an open-source tool designed for building, scheduling, and tracking complex workflows and data pipelines, with robust flexibility and broad integration options.
How to create a Data Pipeline with Apache Airflow?
To create a data pipeline with Apache Airflow, start by installing Docker files and setting up the UI. Then, create a DAG file, extract lines with exceptions, pull the required fields, and query the table to generate error records.
Apache Airflow Pros
- Provides a flexible and scalable solution for managing data pipelines
- Strong, active community support for troubleshooting and best practices
- Enables task monitoring with options to set alerts
Apache Airflow Cons
- As an open-source platform, it often requires in-house expertise to manage dataflows effectively
- Scheduling can be slow, especially when handling numerous tasks
- Heavily reliant on Python for creating DAGs, making it limiting for teams without strong Python expertise
Apache Airflow Pricing
Free.
Apache Kafka
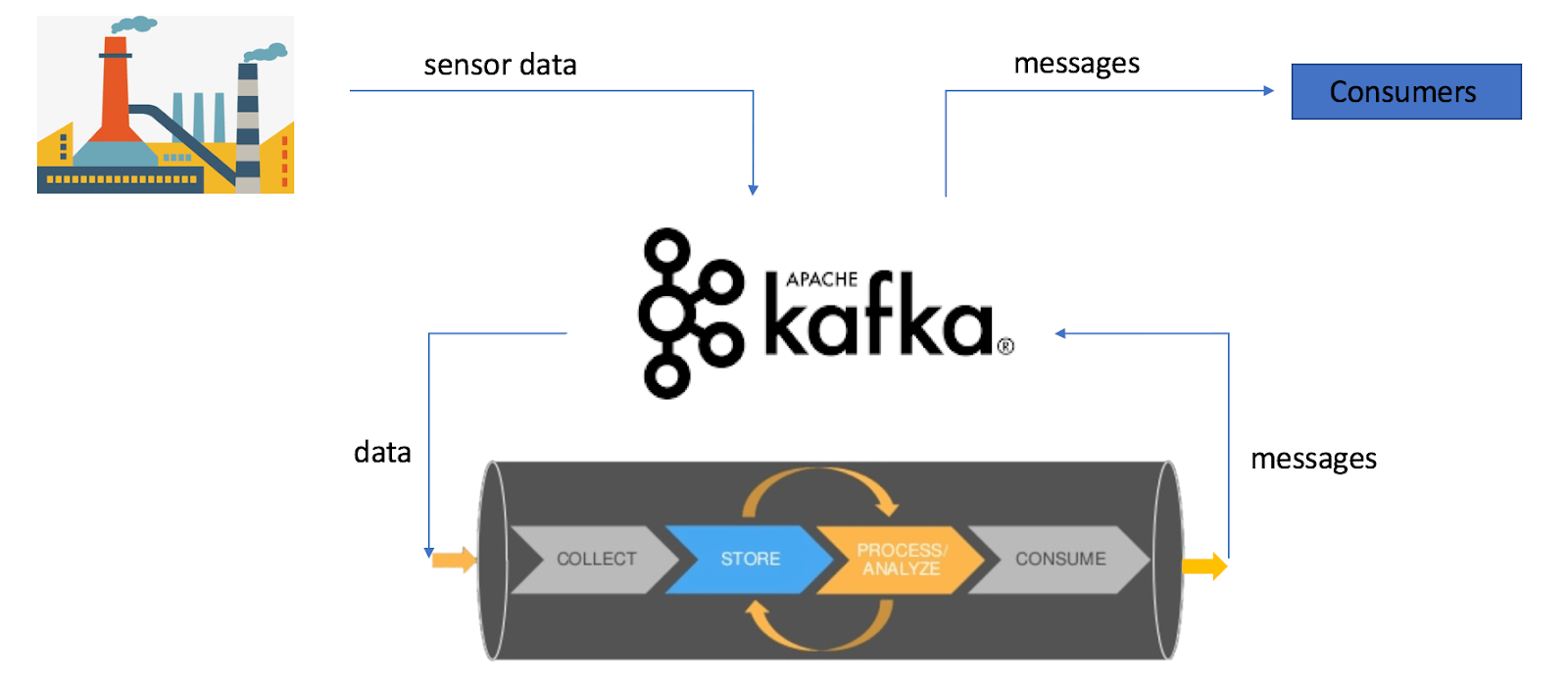
Apache Kafka is an open-source platform for ingesting and processing data in real-time. It uses a distributed messaging system, where producers publish messages to topics, and consumers (like databases or downstream applications) subscribe and process these messages instantly.
How to create a Data Pipeline with Apache Kafka?
To create a data pipeline with Apache Kafka, set up a Kafka cluster and configure producers to send data to topics. Consumers then subscribe to these topics to process the data in real-time. This setup enables efficient and scalable data streaming across systems.
Apache Kafka Pros
- Real-time data processing
- Scales horizontally to manage large data volumes
- Provides fault-tolerant replication for critical data
Apache Kafka Cons
- Steep learning curve, especially for advanced configurations
- Overkill for simple or low-volume data tasks
- Infrastructure and operational costs for cluster management
Apache Kafka Pricing
Free.
Informatica PowerCenter
Informatica PowerCenter is a powerful ETL tool designed to extract, transform, and load data from multiple sources, with advanced features for managing data integration at scale. It’s widely used in enterprise environments to ensure data quality and consistency.
How to Create a Data Pipeline Using Informatica PowerCenter?
To create a data pipeline using Informatica PowerCenter, first define the source and target data systems within the workflow. Then, use the Designer tool to create mappings for data extraction, transformation, and loading (ETL). Finally, execute the workflow to automate data movement and processing.
Informatica PowerCenter Pros
- Provides robust data quality management features
- Efficiently handles high data volumes
- Includes a range of built-in connectors for diverse data sources and destinations
Informatica PowerCenter Cons
- High resource requirements for processing large datasets
- Licensing costs are high, making it less accessible for smaller businesses
- Difficult to integrate code from other languages such as Java, Python, and R
Informatica PowerCenter Pricing
Custom pricing.
Talend
Talend is a data integration and ETL (Extract, Transform, Load) tool that simplifies building and managing data pipelines. It provides a drag-and-drop interface and pre-built components to connect, transform, and move data across different systems.
How to create a Data Pipeline with Talend?
To create a pipeline from scratch, go to Pipelines > Add pipeline, name it, and add a Source by selecting or creating a dataset. Use the Plus icon to add processing components (e.g., filtering, cleansing, aggregating), then add a Destination for data output. Preview data at each step before execution.
Talend Pros
- Pre-built big data connectors for platforms such as Hadoop, Spark, and NoSQL databases
- Specialized components for big data processing tasks
- Parallel processing for efficient large dataset handling
Talend Cons
- The extensive range of functions and features can be overwhelming for beginners
- Limited options for customization
- Limited support for modern cloud-native architectures
Talend Pricing
Custom pricing.
Onetab.ai: Your Pipeline to Success
Data is the fuel that powers businesses of all shapes and sizes. As such, you need a healthy data pipeline for a healthy workflow.
Building a data pipeline spans collection, processing, and transformation to power meaningful insights from large volumes of data. The resulting pipelines streamline data management, feed informed decision making, and add data-driven accuracy. Regardless of the application, selecting the right data pipeline tools is vital for benefiting from the promised benefits.
While there is no dearth of options, sign up for Onetab.ai and experience the difference for yourself!